The groan heard 'round the world.
This week brought news that Elon Musk is mulling a purchase of Twitter, which until now had been holding onto its place as my "favorite" social media platform (insofar as one can enjoy any social media platform). For all of its flaws, I've made great professional connections on Twitter, and I'm not eager to see what it's going to become if/when it reforms as the privately-held company and personal playground of the "free speech absolutist"/world's richest man.
While I'm waiting to see whether all of the friends, writers, artists, and tech geeks I follow on Twitter are going to leave the platform, I'm going to be proactive in taking back some of my own content before anything bad happens to it. (Make backups! It's only a matter of time.)
As I announced in my last post, this website now runs on Eleventy, a static site generator created and maintained by Zach Leatherman. Zach gave a useful talk a few years ago on owning your own content on social media, the content of which served as a great guide for this process. We're going to follow a modified version of Zach's process to create a Twitter archive.
Step One: Get your Twitter data.
Quick note: it might take Twitter more than 24 hours to provide you with your archive once you request it, so be patient!
-
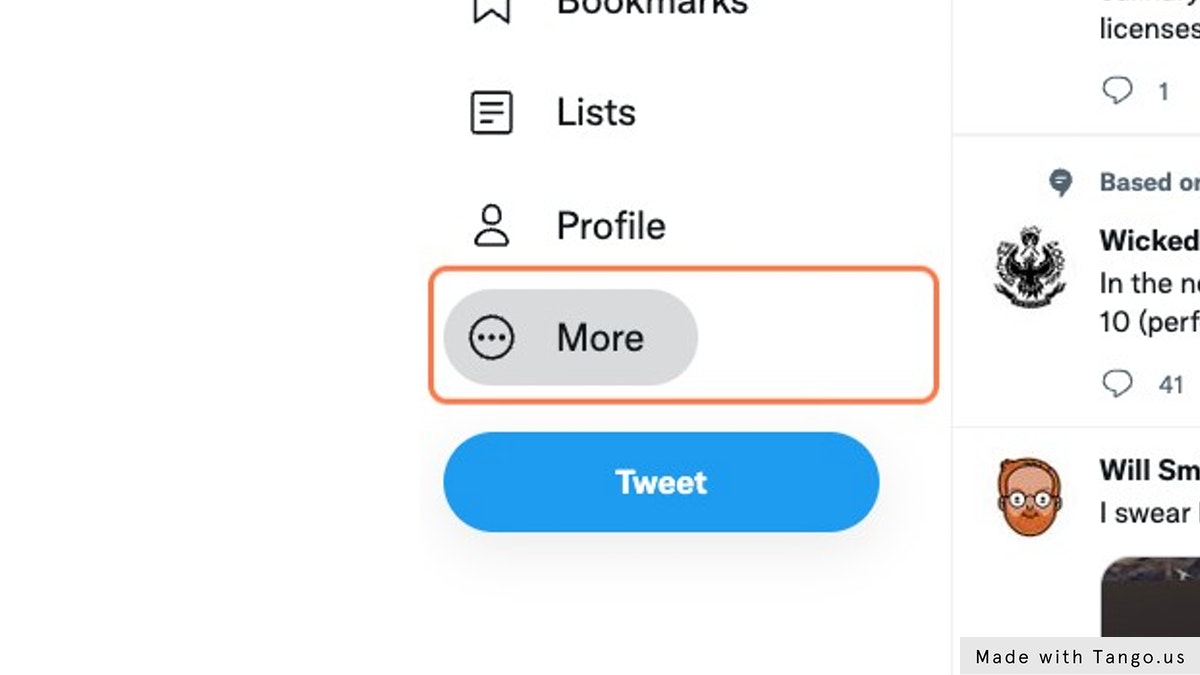
Click on the More settings button
-
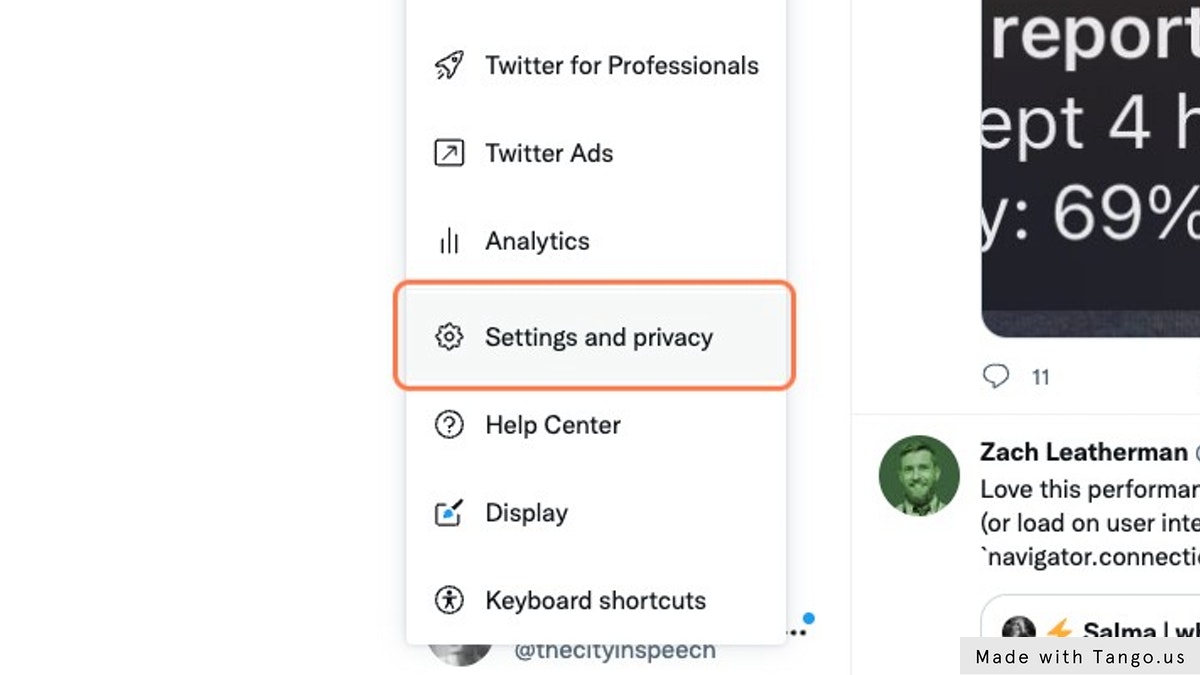
Click on Settings and privacy
-
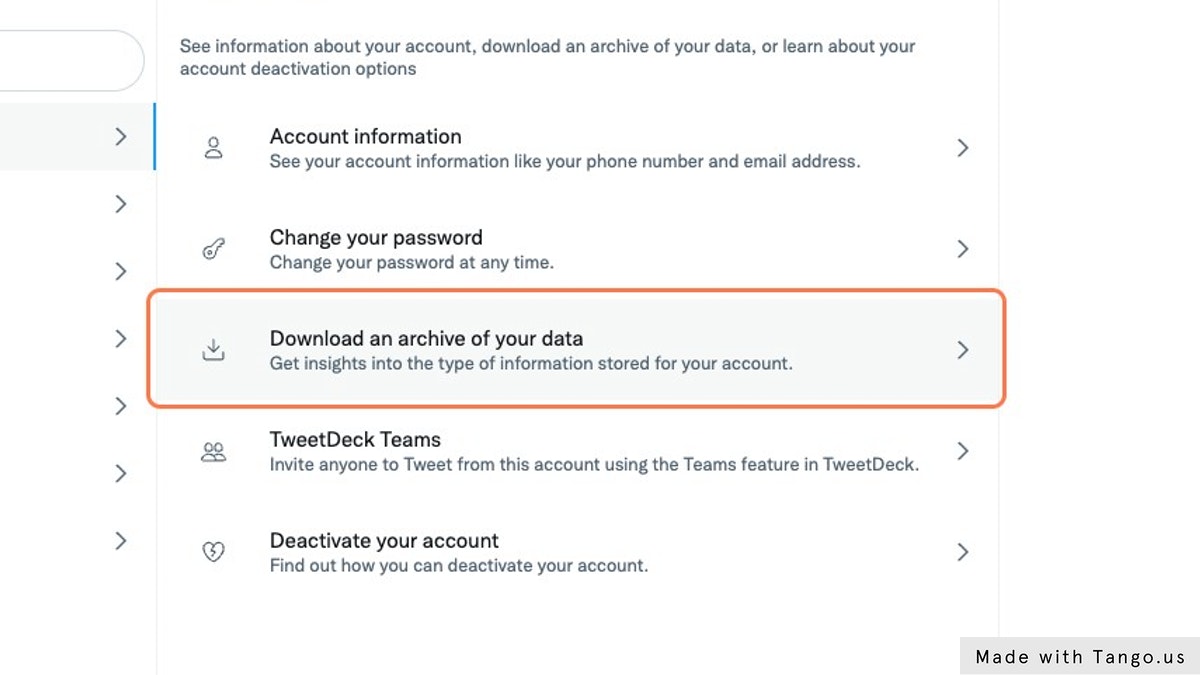
Click on Your Account -> Download an archive of your data
-
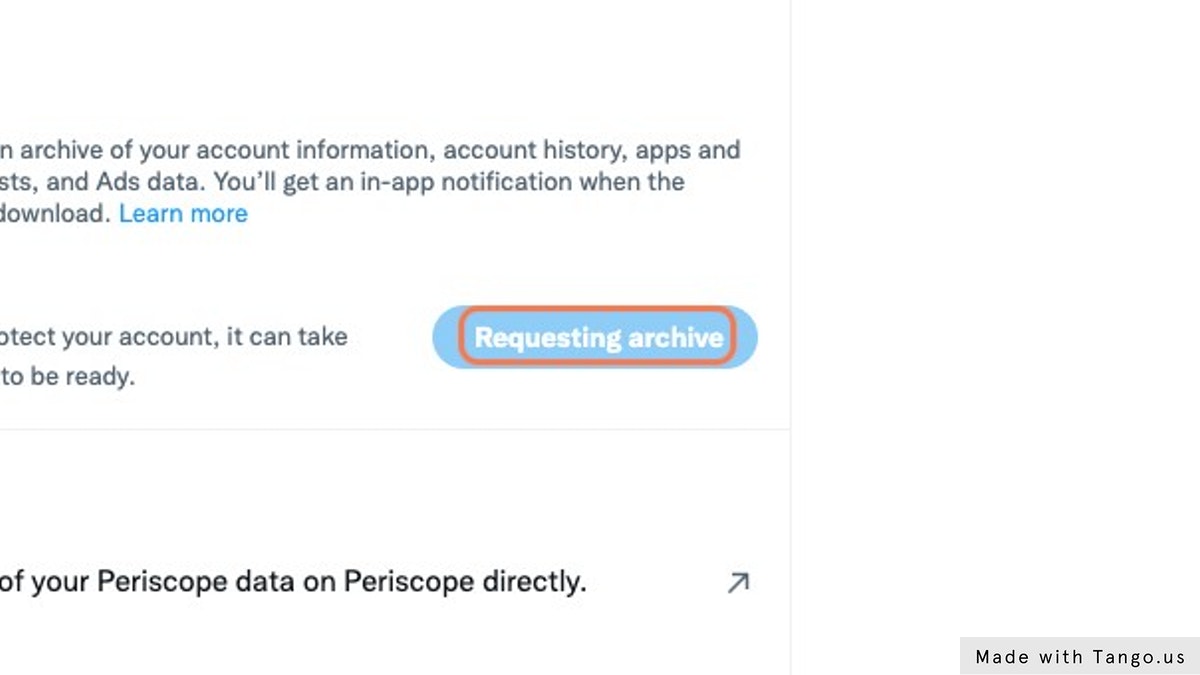
Click to request your data archive
Step Two: Create your archive.
-
Once you've downloaded your archival Twitter data, extract the zip file, navigate to the data/ folder, and find the file named "tweet.js." We're going to use our data to create a new page for each Twitter post. Copy the tweet.js file to your _data/ directory in your 11ty project.
-
Open up tweet.js. The very first line should look like this:
window.YTD.tweet.part0 = [
Change it to the following so that we can treat this as JSON data.
[
In addition, change the file ending from .js to .json.
- Create a directory to hold all of your tweets. I'm going to create mine at twitter/ in the 11ty root directory. Inside that folder, create a file called index.liquid and drop in the following frontmatter:
---js
{
layout: "layouts/default.html",
pagination: {
data: "tweet",
size: 10,
alias: "tweet",
reverse: true,
before: (paginationData, fullData) => paginationData.map((d) => ({
...d,
tweet: {
...d.tweet,
tweet: {
...d.tweet.tweet,
created_at_parsed: new Date(d.tweet.created_at)
}
}
})).sort((a, b) => a.tweet.tweet.created_at_parsed - b.tweet.tweet.created_at_parsed)
},
}
---
Content stuff goes here!
As you can see, I want my tweet archive to use a default layout created in _includes/layouts. The important requirement here is in the before callback that occurs prior to the pagination logic. This callback is used to sort the data by date, and we need to do this because Twitter's data is not in chronological order. (Why? I dunno!) This callback also necessitated us writing our frontmatter in JavaScript-- functions won't work in YAML or other frontmatter formats.
- Create a layout for individual tweet pages. For ease, I put mine in the project root at tweet-layout.liquid. Here's the frontmatter from mine, again in JavaScript:
---js
{
layout: "layouts/default.html",
tags: ["tweet"],
pagination: {
data: "tweet",
size: 1,
alias: "tweet",
},
permalink: "twitter/undefined/index.html",
eleventyComputed: {
date(data) {
const _date = new Date(data.tweet.tweet.created_at);
data.page.date = _date;
return _date;
}
}
}
---
Content stuff goes here!
The important part here, as you might guess, is in the eleventyComputed property, wherein we are once again using a quick JavaScript function to convert the each tweet's date to a date object that we then inject into the 11ty page data for use by our pagination process. This is a little hacky (due to the way 11ty looks at page dates by default), but it works.
- Build your 11ty project! You should now have a Twitter archive created from your exported data. Check out my archive and an individual tweet page below!
https://www.chadams.me/twitter/
https://www.chadams.me/twitter/1519417069963468815/
Indie web folks would look at the process we just went through as an example of "Publish Elsewhere, Syndicate (to your) Own Site," or PESOS. I hope you found this useful! Thanks for stopping by, and long live the indie web!